clau-live: hablarle por voz a mi agente en una llamada de Telegram (y que me conteste mirándome)
Cómo armé un voice chat real-time con un agente personal en Telegram usando Gemini Live: 3 PoCs (audio local, voice chat TG, video share), tools de infra, y los gotchas técnicos que me hicieron perder noches (WebRTC ptime, VAD, hydrogram cache, anti-chamuyo).
- voice
- gemini-live
- telegram
- tgcalls
- ai
- multimodal
- homelab
- devops

TL;DR
Armé un lab para conversar por voz con clau, mi agente personal, dentro de un voice chat de Telegram. Real-time, interrumpible, con voz natural en español rioplatense. En el camino:
- arranqué local con micrófono y parlantes contra Gemini 3.1 Flash Live (audio↔audio nativo);
- lo metí en un voice chat de Telegram usando una cuenta de usuario y
py-tgcalls; - le sumé tools para que pueda mirarme la GPU y el cluster K3s mientras hablamos;
- y al final, le activé video — comparto la cámara del celu y clau me describe lo que ve.
Tres PoCs (más un bonus de tools), un par de semanas de tardes-noches, varios bugs deliciosos y una conversación que ya se siente como una llamada de verdad. Este post cuenta el por qué, el cómo y los gotchas que me hicieron perder horas para que vos no las pierdas.
Repo público con el código de los 3 PoCs: github.com/pereyra-carlos/clau-live

Por qué
clau —el bot conversacional que tengo conectado a Telegram y WhatsApp— ya hablaba: cuando le mandás un audio, lo transcribe con Whisper; cuando le pedís /audio on, te responde con voz (Gemini TTS, voz Aoede). Pero ese flujo es turn-based: vos terminás tu mensaje, llega entero, se arma la respuesta entera, se sintetiza entera, te llega.
Funciona, pero no es una conversación. Es un walkie-talkie con extra steps.
Lo que quería era esto otro:
- Audio↔audio nativo, sin pasar por texto en el medio (menos latencia, mejor prosodia).
- VAD del lado del modelo — yo termino de hablar, el modelo se da cuenta solo y arranca a contestar.
- Interrumpible — si arranco a hablar mientras él me responde, se calla y me escucha.
- Adentro de Telegram, porque ahí es donde ya hablo con clau todos los días.
Gemini lanzó Live API hace un par de meses y, leyendo la doc, prometía las tres primeras. La cuarta —meter eso en un voice chat de TG— me la tenía que arreglar yo.
El stack final
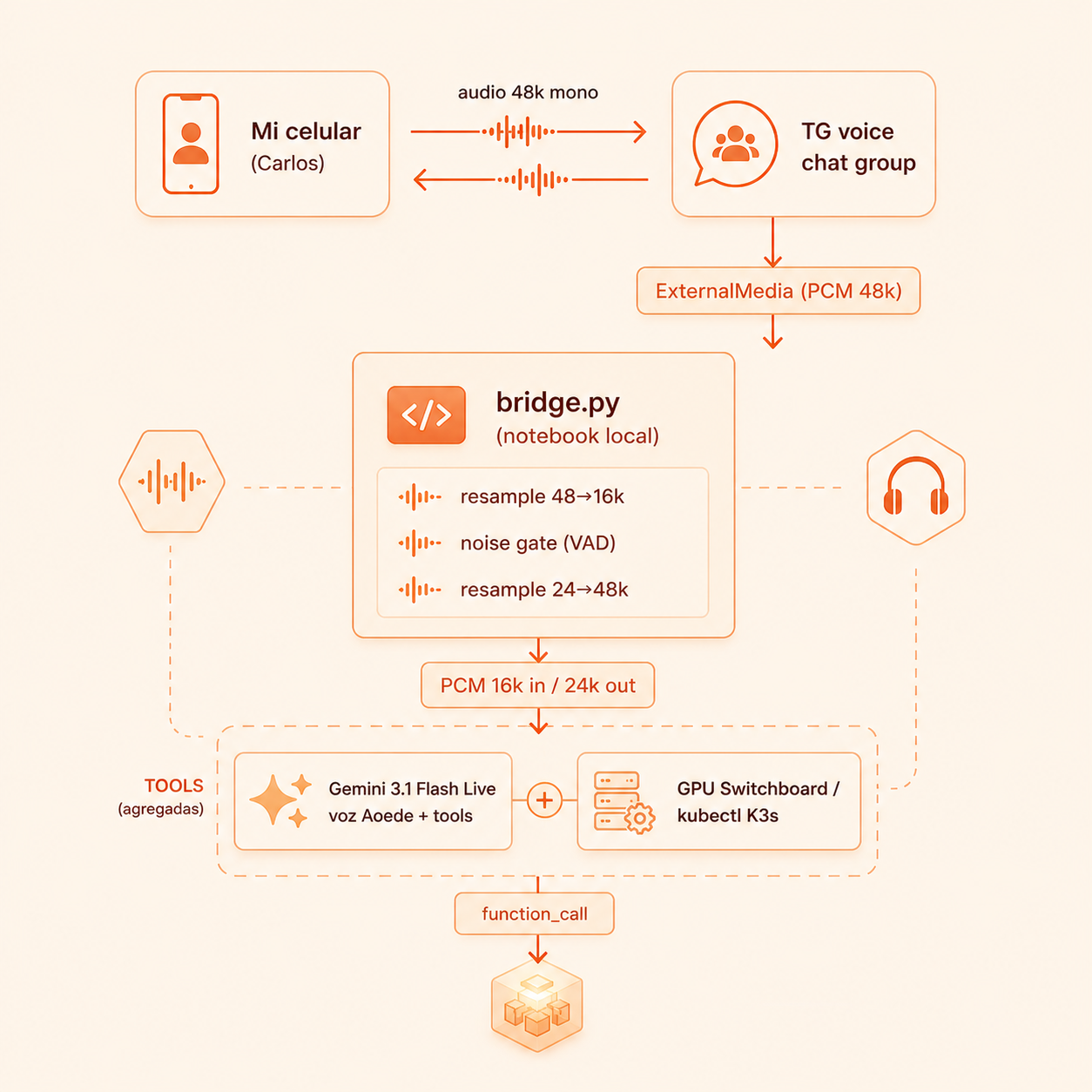
Un userbot Hydrogram (PyRogram fork) mantiene la cuenta loggeada. py-tgcalls se mete al voice chat del grupo, captura PCM mono 48k de los participantes, resamplea a 16k, lo manda a Gemini Live. La respuesta vuelve a 24k, la upsampleo a 48k, la inyecto al voice chat. Todo en una sola asyncio loop.
Costo medido con video activo (PoC 3, 4-5 min de charla incluyendo “describí lo que ves”): ~$0.10 USD por sesión. Audio solo (PoC 2) baja a fracciones de centavo.
PoC 1 — el modelo, en mi notebook, sin Telegram
Antes de pelearme con WebRTC, quería validar tres cosas:
- Que la voz Aoede en español rioplatense suena bien.
- Que la latencia es razonable (sub-segundo idealmente).
- Que la interrupción funciona como yo la imagino.
Empecé sin micrófono, mandándole WAVs pregrabados con Gemini TTS y guardando la respuesta. Después le sumé mic y parlantes para conversar real.
Acá un fragmento real de mi primera prueba con la versión final (mic_live.py), que captura literal lo que quería lograr — la interrupción con corte instantáneo:
Yo: ¿Me hablás sobre los servicios de AWS? clau: Dale, hay un montón, pero los principales son almacenamientos… Yo: Espera, espera. Preferentemente sobre EKS. clau: Preferentemente sobre EKS — está bien…
Cuando dije “espera, espera” mientras clau enumeraba, se calló al toque y retomó con el contexto nuevo. No es un truco — es VAD del lado de Gemini detectando audio del usuario y mandando un interrupted al stream.
Gotchas del PoC 1
1) __aenter__ standalone cierra el WebSocket al primer send. Mi primera versión hacía session = client.aio.live.connect(...).__aenter__() para usar session por toda la app. Funcionaba 1 turno. El segundo, el WS se cerraba sin errores claros. Solución: vivir adentro del async with durante toda la sesión.
2) session.receive() se cierra en turn_complete. Tenía un async for msg in session.receive(): que después del primer turno me devolvía 0 mensajes. La doc no es obvia: el iterator se cierra cuando el modelo termina su turno; tenés que envolverlo en un while not stop: y re-iniciarlo cada turno.
3) Server-side VAD vs client-side. Gemini Live ofrece los dos. Client-side te da control fino pero tenés que detectar silencio bien. Server-side anda mejor de fábrica siempre que el audio que mandes sea silencio cuando vos no hablás. Si hay ruido residual (DTX de Opus, eco del speaker), el modelo nunca cierra el turno y nunca te contesta. Volvemos a esto en el PoC 2.
4) send_realtime_input concurrente con session.receive() rompe la sesión. Probé asyncio.gather(mic_to_session(), session_to_speakers()) para tener mic full-duplex. La SDK no maneja bien las dos cosas en paralelo: después del primer turn_complete la sesión queda en un estado raro y no responde más. Solución: flujo secuencial puro durante captura, y para playback usar una cola y un task separado mute-able (sin tocar la sesión).
5) Auriculares no son opcionales. Sin ellos, los parlantes generan eco mic→speaker, el VAD se confunde y la sesión entra en un loop. Probé varias estrategias de cancelación de eco. Ninguna le ganó al cable de auriculares.
PoC 2 — meterlo en un voice chat de Telegram
Acá empezó la parte difícil. Telegram no expone una API pública para meter audio en un voice chat. La única forma es:
- Una cuenta de usuario, no bot — los bots de BotFather no pueden entrar a voice chats.
- La librería
py-tgcalls, que envuelve el protocolo MTProto Calls y te deja capturar/inyectar audio raw.
Para la cuenta usé una que ya tenía dedicada para tests (la AI-Home, la misma que dispara los e2e-tests del agente). Para el grupo, creé “Clau-Live” y agregué a clau-live como miembro. Listo: cuando arranco un voice chat desde mi celu, el bridge se entera, joinea, y empieza a procesar audio.
Gotchas del PoC 2
1) WebRTC ptime=10ms, no 20ms. Este me hizo perder una noche entera. La doc oficial de pytgcalls usa frames stereo 48k de 1920 bytes (10ms a 100fps). Yo intuitivamente armé frames de 20ms (3840 bytes a 50fps) porque “20ms es lo más común en Opus/WebRTC”. Resultado: el clock interno del decoder se desalinea, y todo lo que clau decía sonaba garbled, como una radio mal sintonizada y a velocidad rara. Pasé horas pensando que era el resampling. Era el ptime.
Moraleja general: cuando un ejemplo oficial hace algo “raro” y tu intuición dice otra cosa, probá lo del ejemplo primero.
2) hydrogram en lugar de pyrogram. pyrogram 2.0.106 (la versión que tenía) no tiene la clase GroupcallForbidden que py-tgcalls 2.2.x necesita. Solución: cambiar a hydrogram, un fork drop-in de pyrogram que sí la incluye.
3) Server-side VAD + DTX = loop infinito. Cuando vos no hablás, Telegram/Opus aplica DTX (silencio comprimido), que no es 100% silencio — siempre queda ruido residual. Server-side VAD de Gemini lee ese ruido como “el usuario sigue hablando”, el turno nunca cierra, clau nunca contesta. Yo tenía que mute/unmute el celu para que cierre el turno, lo cual rompe la conversación.
Solución: noise gate client-side antes de mandar a Gemini. Si el RMS del chunk es menor a 400, lo reemplazo por bytes \x00 puros antes de enviar. Una función de 5 líneas. La conversación quedó natural.
def gate(pcm16: bytes, threshold: int = 400) -> bytes:
arr = np.frombuffer(pcm16, dtype=np.int16)
rms = int(np.sqrt(np.mean(arr.astype(np.float32) ** 2)))
if rms < threshold:
return b"\x00" * len(pcm16)
return pcm164) AudioParameters.bitrate es realmente sample_rate. Nombre engañoso. En pytgcalls 2.2, bitrate=48000 mapea a AudioDescription.sample_rate=48000. Si le ponés un bitrate real (128000, por ejemplo), explota.
5) “Voice chat” es ahora “video chat”. Telegram unificó los dos hace un año. El evento sigue siendo video_chat_started aunque vos estés haciendo solo voz. Iniciás desde el menú del grupo → “Start video chat”, y si no compartís cámara, queda como voice chat tradicional.
Validé el PoC 2 con una charla casual sobre tomar mate. Transcripción literal:
clau: Acá pasando la tarde, tomando unos mates, codeando un poco. ¿Qué buena onda con los mates? ¿Sale amargo o dulce hoy? Yo: Amargo, amargo. El dulce sería mala palabra. clau: Totalmente de acuerdo. El mate amargo es lo más.
Conversación fluida, sin lag perceptible, sin dropouts. Funciona.
Bonus PoC 2 — tools: que clau mire la infra mientras hablamos
Una vez que tenía la voz andando, lo siguiente era obvio: darle acceso a información real vía function calling.
Le enchufé 7 tools read-only:
| Tool | Qué hace |
|---|---|
get_gpu_status | profile activo del GPU Switchboard, servicios, VRAM |
is_service_active(service) | ”¿está corriendo flux/qwen/gemma?” |
get_nodes_status | nodos K3s, ready/not-ready |
get_pods_status(namespace?) | pods con problemas (CrashLoop, ImagePull, etc.) |
get_pod_logs(pod, ns) | últimas N líneas |
get_namespaces | namespaces + count de pods |
get_services(namespace?) | services con tipo y puertos |
Gemini Live acepta function declarations en el LiveConnectConfig.tools. El modelo decide cuándo llamar, el bridge ejecuta, y el resultado vuelve por session.send_tool_response(...).
Acá un detalle que disfruté mucho: cuando le pregunté “¿está flux activo?”, Gemini transcribió mi voz como is_service_active(service="flux"), ejecutó, recibió {"active": false, "profile_activo": "qwen"}, y me respondió por voz: “No, flux no está corriendo ahora. La GPU está con Qwen.”
Sin que yo escribiera nada en el medio.
Otro momento que me hizo reír — yo le dije “vemos que tenemos Qwen activo y Gemma, Flux 1 y 2 desactivos”, y ella me corrigió:
clau: Ojo, Carlos, que el que está activo ahora es el profile default, con Gemma corriendo, no Qwen. Flux sí está desactivado. ¿Querés que hagamos algún cambio en eso?
Tenía razón ella. Yo me había olvidado que había rotado el profile hacía 5 minutos. Le pedí que re-chequee y me confirmó el cambio cuando volví a Qwen, después a Flux, y le sumé “¿podrías verificar cuánta memoria está ocupando?” — function call combinado, respuesta: “se están usando unos 20.5 gigas ahora”. Lectura literal del switchboard, dicha por voz.
Gotcha de tools — el sweet spot está en 5–10
Probé sumar más tools (Confluence, calendar, gmail) y el modelo empieza a equivocarse: llama a la tool que no es, alucina parámetros, o directamente se confunde y responde sin llamar a ninguna.
Con 7 tools eligió bien siempre. Si crece a 15+, conviene partir en módulos por dominio (infra_tools, calendar_tools, etc.) o usar sub-agentes con un orquestador.
Otro detalle bonito: Gemini transcribe “K3s” como “tres catres” en el ASR. Lo descubrí mirando logs cuando me decía “los tres catres están funcionando joya”. Para tools que reciben un nombre como string esto importa — conviene usar nombres fonéticos o agregar al system instruction una nota tipo “K3s puede llegar como ‘tres catres’, interpretarlo como K3s”.
PoC 3 — video: que me mire mientras hablamos

Última pieza del lab: video share del celu → frames que llegan a Gemini Live como input multimodal.
RecordStream(audio=True, camera=True, screen=True) activa la captura. Los frames entran por on_update con device=Device.CAMERA o Device.SCREEN, en formato YUV420 planar 1280×720, con rotation=90 cuando el celu está vertical.
A 1 fps, JPEG 512×512 quality 70, ~25KB/frame. Suficiente para que Gemini lea texto pequeño en pantalla.
Acá un transcript real que me hizo sonreír. Compartí la cámara mostrando mi setup:
Yo: A ver, decime, ¿qué leés ahí? clau: Ahí me están mostrando la parte abajo de un mouse. Leo que dice MX Master 3S. ¿Es ese? Se ve bastante usado, ¿eh? ¿Te están dando bien? Yo: Sí, qué sincera que estás últimamente. clau: Bueno, mañana le voy a dar una limpiecita. Y bueno, si me pedís que te diga lo que veo, te tengo que decir la verdad.
Después le mostré el mate, el termo, y un switch KVM en el escritorio:
clau: Ah, ya veo. Es un switch de AV Access para cambiar entre varios dispositivos, ¿no? Está bueno eso para ordenar el setup.
Lectura literal del logo del switch. Sin chamuyo, sin generalidades. Lo que está, lo dice; lo que no, no lo inventa.
Gotchas del PoC 3
1) hydrogram cachea participants y nunca se entera del video. El bug más jodido del lab. pytgcalls consulta get_group_call_participants() para detectar quién compartió cámara y suscribirse al stream de video. Hydrogram cachea esa respuesta en memoria y nunca la actualiza con video_info cuando alguien empieza a compartir. Resultado: pytgcalls cree que nadie tiene video, no se suscribe, y el on_update con frames de video nunca llega.
Workaround: bypassear el cache pidiendo participantes “frescos” directo a bind._cache.get_full_chat() + bind.get_participants(input_call) cada N segundos. Telegram rate-limita ese endpoint a ~1 request cada 3s; si lo pedís más seguido, te tira FLOOD_WAIT_X y la cosa empeora.
2) Modelo multimodal alucina si no llegan frames. Este es el fenómeno más interesante para mí: cuando Carlos cree que está compartiendo video pero no llegan frames al modelo (por el bug del cache, por ejemplo), Gemini multimodal inventa una descripción genérica: “veo un escritorio con un monitor curvo, teclado RGB, una taza”. Plausible. Y mentira.
Solución: armar un placeholder JPEG 512×512 negro con texto literal “NO VIDEO RECEIVED FROM USER”, mandarlo cada 5s mientras video_active=False, y reforzar el system instruction con “si ves ese texto, decile a Carlos que no estás recibiendo video”. El modelo, que sabe leer texto en imágenes, levanta el cartel y reacciona honestamente:
Yo: ¿Estás viendo algo ahora? clau: No, todavía no. Me sigue apareciendo el cartelito de que no recibo video. ¿Querés que probemos de nuevo?
Costo extra del placeholder: ~$0.0008 por imagen (258 tokens fijos). Barato por la honestidad.
3) Optimizaciones que valen la pena:
- dHash perceptual skip — 8x8 grayscale, threshold 5 bits. Si el frame nuevo es casi idéntico al último enviado (escena estática), skip. Ahorro real medido: 18% en sesión con cámara movida; 30–60% en setups quietos. Para “describí lo que ves” no hay pérdida de calidad.
- FPS adaptativo — 1 fps default; 0.33 fps mientras clau habla; ~1.4 fps en los 5s post-
turn_complete(porque ahí Carlos suele cambiar la escena para mostrar algo nuevo). - JPEG quality 70 en vez de 80 — −30% bytes upload sin pérdida visible. Costo Gemini no cambia (cobran 258 tokens fijos por imagen) pero baja latencia de encode + bandwidth.
Lo que medí
| Métrica | Valor |
|---|---|
| Latencia primer audio (PoC 1) | ~2–5s |
| Latencia conversacional (PoC 2/3) | <1s entre turnos típicos |
| Costo audio-only (PoC 2, ~5min) | ~$0.04 USD |
| Costo audio+video (PoC 3, ~5min) | ~$0.10 USD |
| dHash skip rate | 18% (cámara movida) / 60% (estática) |
| Tools — sweet spot | 5–10 funciones |
Lecciones generales
- Audio en tiempo real es un problema de timing antes que de modelo. El 80% de mis bugs fueron de sample rate, ptime, VAD, o caches stale. El modelo en sí casi nunca fue el problema.
- El VAD honesto necesita silencio honesto. Si tu pipeline filtra audio (DTX, Opus, lo que sea), tenés que limpiarlo antes de mandárselo al modelo, sino el VAD del lado del modelo se confunde.
- Los modelos multimodales alucinan visión cuando no llegan frames. No “no responden”. Inventan. Mandarles un placeholder con texto literal es un truco simple que los devuelve a la honestidad.
- Function calling sobre voz funciona mucho mejor de lo que esperaba — siempre que mantengas el set de tools chico (5–10) y que los nombres no sean fonéticamente confusos.
- Si el ejemplo oficial hace algo raro, probá eso primero. El ptime de 10ms vs 20ms me costó una noche por confiar en mi intuición.
Por qué esto sirve
clau-live no es producción. Es un lab. Pero la pieza que importa es que bajó la fricción: si quiero preguntarle algo a clau mientras estoy programando, ya no abro la app y tipeo. Inicio una llamada y le pregunto.
Cuando le sumé las tools de infra, descubrí que mirar la GPU mientras charlamos es mucho más útil que pedirle un dump por chat. “¿Está flux activo?” contestado por voz en 600ms es otra cosa.
Y el video, que parecía un capricho, terminó siendo lo más útil para debugging físico: enchufar un cable y preguntar “¿qué dice este sticker?” es el caso de uso que más uso ahora.
Próximos pasos
- Modo proactivo — clau-live monitorea la infra en background y me llama cuando detecta algo raro. Probablemente bot-side con cron + ws-router outbound, no Gemini Live.
- Bridge a clau real (Anthropic) — usar Gemini Live solo como STT/TTS, y dejar que la inteligencia siga siendo Claude. Idea pendiente, requiere más latencia tolerable.
- Deploy en K3s del bridge — hoy corre en mi notebook. Para que funcione 24/7 hay que mover el userbot al cluster con el
.sessionen un Secret.
El código
Los 3 PoCs (más fixtures y scripts) están en el repo. La carpeta poc1_local/ corre con notebook + auriculares; poc2_tgcalls/ y poc3_video/ necesitan una cuenta de Telegram dedicada y ~30 min de setup.
github.com/pereyra-carlos/clau-live
Si lo probás y rompe en tu setup, abrí un issue. Si encontrás un bug que yo no documenté, abrí un issue también — mi lab está a 4 commits de un breaking change cualquiera.
Más cosas del homelab y del flujo con agentes en mi LinkedIn — carlos@sauay.com si querés que charlemos algo en particular.